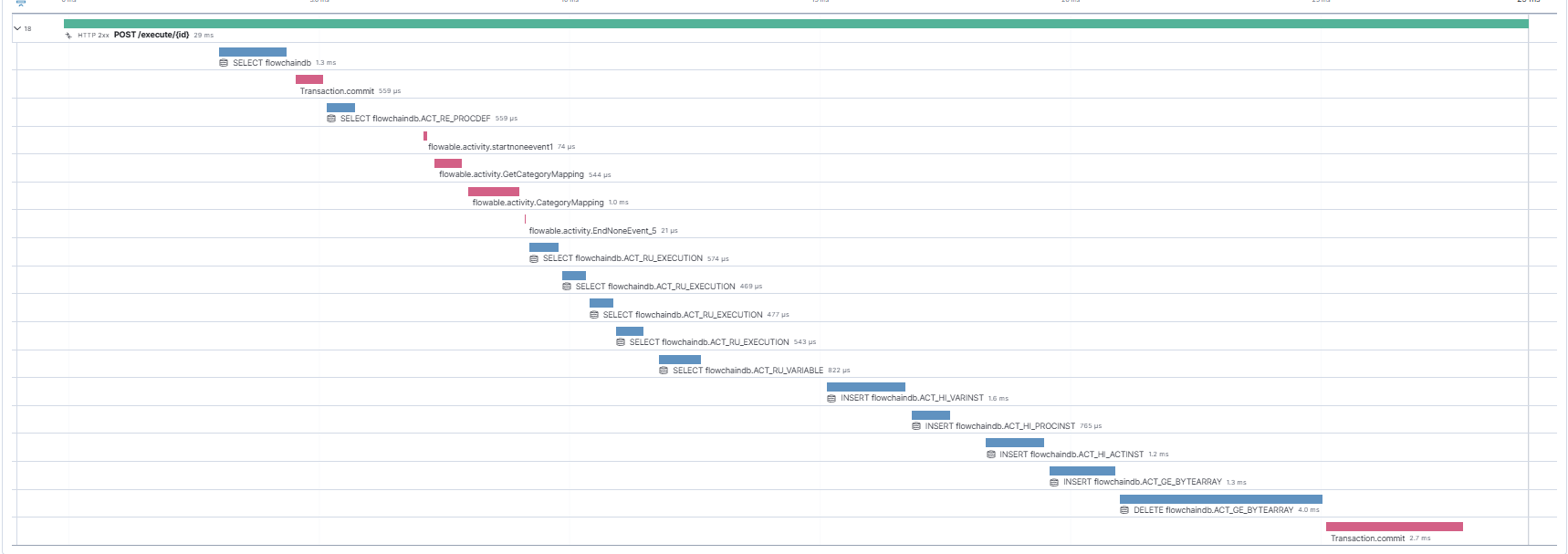
I’m currently using Flowable 7.1 in a performance-critical application where my primary use case involves synchronous process execution. I’ve attached a trace (see image) showing one such request, where most of the execution completes quickly, but the history table writes within the same transaction (e.g., ACT_HI_PROCINST, ACT_HI_ACTINST, ACT_HI_VARINST, etc.) contribute non-trivial time and introduce unnecessary coupling.
We used to have async history support, i.e. we would create the data that needs to be stored in the history during the runtime, store it in a blob and then read that and populate the history in another transaction. However, there were some problems with that approach, there was also time spend in computing the history during the runtime and storing it in the same transaction.
In any case, have you looked into tweaking the history level for your processes?
Depending on the level it the variables and / or the activity instances can be ignored in the history tables.
I see that there are inserts and deletes from the ACT_GE_BYTEARRAY table. This usually indicates that you are either using large string / json variables (that do not fit in the text_ column in the variable instance table) or that you are using serializable variables. I would advise you to review that part.
I also see that there are 4 select from the ACT_RU_EXECUTION table when a process is completed, but I think you know already from Process variables in synchronous execution that this would already be optimized.
If you would like to hook in different type of history logic, then I would suggest that you look into the HistoryManager. You can check how the async history used to work in Flowable 6 if you are interested in that. However, since our implementation was guaranteeing consistency, (i.e. if there was a failure in the runtime transaction), we were not storing the history data. However, this did mean that we had to do some additional logic which had certain implications on the length of the transactions.
Thanks for the explanation. I understand that whether the history is committed within the same transaction or written to a blob, it will still require computation time. I also need to keep the history level set to Activity, as we want to provide users with detailed insights into what happened at each step.
My concern is that when a transaction fails, no history is recorded—as if the execution never occurred. While I understand that technically everything is part of the same transaction and a rollback removes data from all tables, from a functional standpoint users should still be able to see that a workflow execution failed, including the step where it failed and the reason for the failure.
To address this, we are capturing the exception, writing it to a custom audit failure table, and merging its results with the history table, allowing us to track both failed and successful workflow executions.
There are multiple ways to achieve a “trace” here. When it’s more about the user who is submitting the task, then you can go ahead and make the next step after the user task async. With that, it’s executed in a separate transaction and you will have the submission of the user task as well as a (timer/deadletter)job to re-execute for the failure. The job also has the exception which occurred.